在微服务架构的实践中,数据一致性一直是一个绕不开的挑战。许多开发者,即使有多年的编程经验,在初次面对分布式环境下的数据管理时,也会感到棘手。特别是负责核心逻辑的数据处理服务,其设计和实现直接关系到整个系统的稳定性和可靠性。
从单体应用到分布式难题
在传统的单体应用中,数据库事务(ACID)为我们提供了强有力的数据一致性保证。一个业务操作可以在一个数据库事务中完成,要么全部成功,要么全部回滚,数据始终处于一致状态。在微服务架构下,业务逻辑被拆分到多个独立部署、拥有独立数据库的服务中。一个完整的业务用例(例如“用户下单”)可能需要调用订单服务、库存服务和支付服务。这时,我们无法再使用传统的跨数据库事务。
数据处理服务,往往是这些业务协同中的关键一环。它可能负责从消息队列中消费事件,进行数据转换、聚合或计算,再写入数据库或触发其他服务。在这个过程中,如何保证“消费的消息”、“处理后的数据”以及“可能触发的后续操作”这三者之间的最终一致性,是设计的核心。
核心模式:拥抱最终一致性
微服务架构倡导的是最终一致性。这意味着系统允许在某一时刻数据存在短暂的不一致状态,但通过一系列的设计,保证在没有新的更新操作后,经过一段时间,所有副本的数据最终会达到一致。对于数据处理服务,以下几种模式至关重要:
- 事件驱动与事件溯源:这是实现解耦和最终一致性的利器。服务之间通过发布/订阅领域事件进行通信。例如,当“订单已创建”事件发布后,数据处理服务可以订阅该事件,异步地更新自己的数据视图或生成衍生数据。事件溯源则将状态的变化记录为一系列不可变的事件日志,数据处理服务可以基于完整的事件流重建或计算状态,这为数据一致性提供了可靠的源头。
- 幂等性设计:在网络不稳定的分布式环境中,消息重复投递或接口超时重试是常态。数据处理服务必须被设计成幂等的。这意味着无论同一个操作(或事件)被处理多少次,其结果都应与处理一次相同。实现方式通常是为每个操作携带一个唯一的业务ID或请求ID,在处理前先检查该ID是否已执行成功。
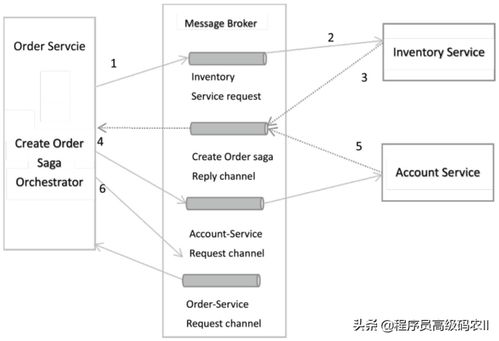
- 事务性消息与补偿机制:对于需要强一致性保证的核心场景,可以采用“事务性发件箱”模式。数据处理服务在本地数据库事务中完成业务操作和“待发送消息”的写入,然后由一个独立的“中继”进程保证消息被可靠地投递到消息中间件。如果后续服务调用失败,则需要有补偿事务(如Saga模式)来执行反向操作,撤销之前已完成的操作,使系统回退到一致状态。
数据处理服务的具体实践
一个健壮的数据处理服务通常会包含以下组件和流程:
- 可靠的事件消费者:从消息队列(如Kafka, RabbitMQ)消费事件,并手动或至少一次语义地确认消费位移,确保消息不丢失。
- 幂等处理器:在处理核心逻辑前,通过检查唯一键(如事件ID+业务ID)来过滤重复消息。
- 本地事务边界:将事件处理与自身数据库的更新严格放在一个数据库事务中。要么同时成功,要么同时失败。这是保证服务内部一致性的基础。
- 异常与重试:对非业务逻辑错误(如网络抖动、数据库临时锁)设计有退避策略的重试机制。对于业务逻辑错误,则应将事件投递至死信队列进行人工干预或后续修复。
- 监控与可观测性:通过日志、指标和分布式追踪,清晰掌握事件的流向、处理延迟和错误率,这是运维数据一致性系统的眼睛。
###
理解微服务下的数据一致性,关键在于思维的转变:从强一致性、集中式控制,转向最终一致性、通过事件进行异步协同。数据处理服务作为这一协同网络中的“转换器”和“计算引擎”,其可靠性建立在事件驱动、幂等设计、事务边界和补偿机制这些基石之上。当这些模式内化于心、外化于行时,构建稳定、可扩展的分布式系统便不再是令人头疼的难题,而是一场充满挑战与成就感的工程实践。